
目录
绪论
- 程序的翻译通常有两种方式:编译和解释。
- 编译程序的功能是将高级语言源程序编译成目标程序,完成高级语言程序到低级语言程序的等价翻译。
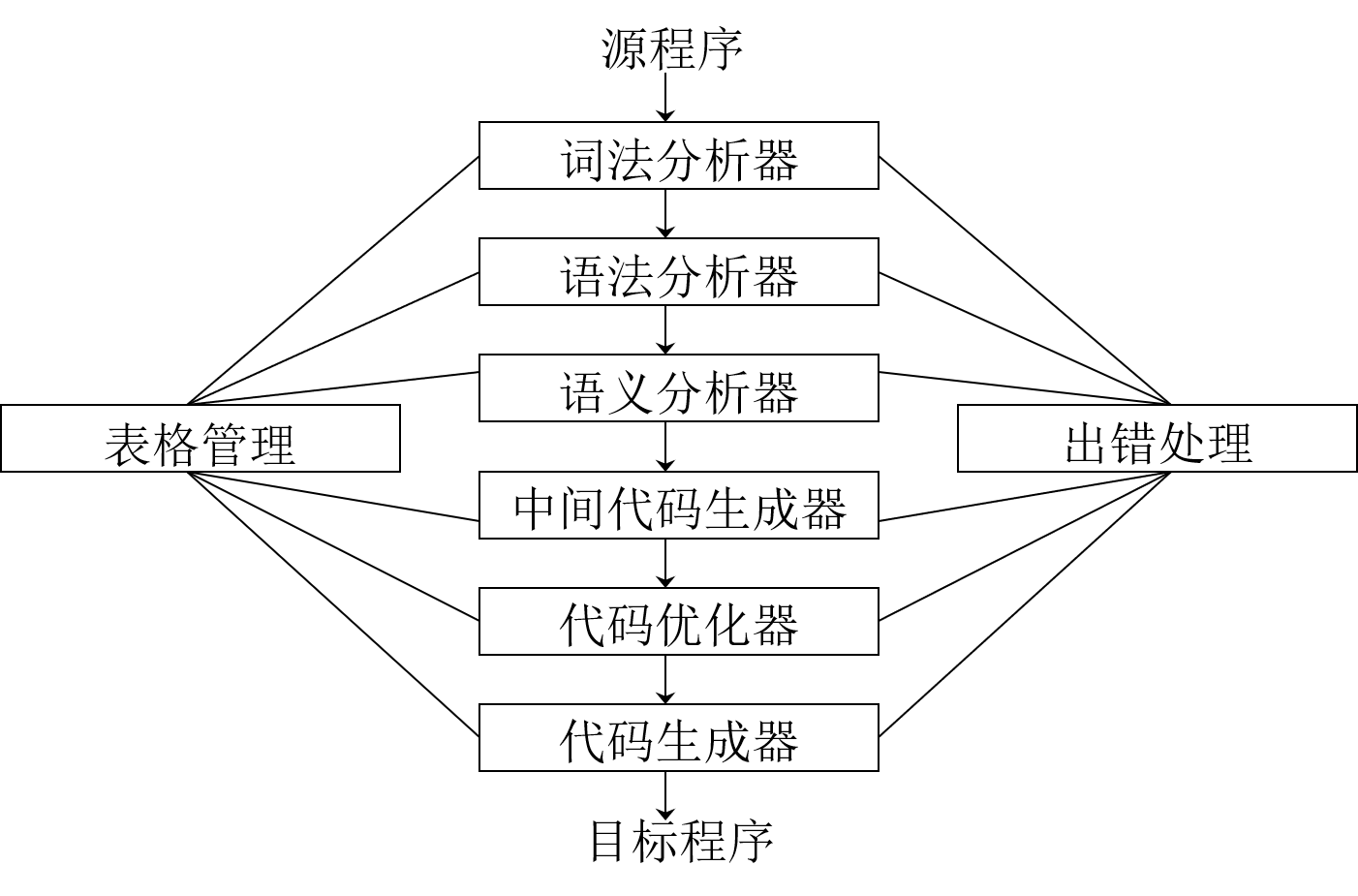
- 编译程序绝大多数时间花在表格管理上。
- 编译程序的工作过程:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成。前三者为分析部分,后三者为综合部分。
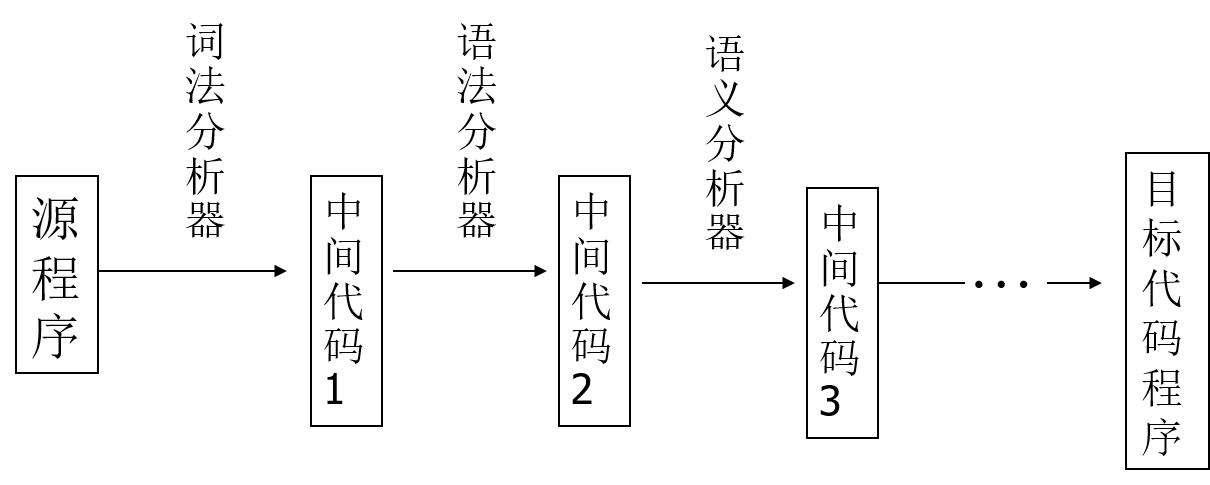
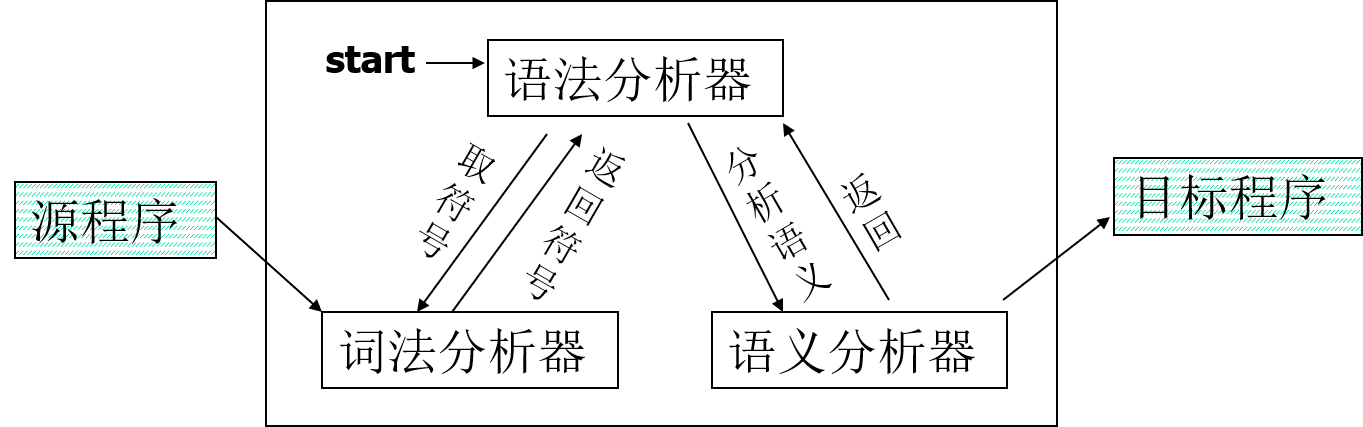
- 一遍(趟)翻译与多遍(趟)翻译。若某语言允许变量先使用后定义,则应采用多遍翻译。
- 多遍翻译:
- 一遍翻译:
- 多遍翻译:
文法与语言
-
- 句型:语法树的叶子从左到右;
- 短语:语法树中每棵子树的叶子从左到右;
- 直接短语:每棵简单子树(只有父子两层的子树)的叶子从左到右;
- 句柄:最左边简单子树的叶子从左到右;
- 素短语:至少包含一个终结符,且不包含其他素短语的短语;
- 最左素短语:语法树最左边的素短语。
- 句型是文法开始符号的广义推导,仅仅由终结符组成的句型叫句子。文法所定义的语言是一个文法中所有句子的集合。
- 对于无二义文法的句型,其句柄是唯一的(对于一个任意的文法,其句柄可能是不唯一的)。
- 如果一个文法存在某个句子,对应两棵不同的语法树,那么该文法二义。
- 不存在一个算法,可以在有限步骤内确切判定一个文法是否二义,即,文法的二义性是不可判定的。
- 四种文法所对应的语言之间的关系:$L3 \subseteq L2 \subseteq L1 \subseteq L0$.
- 0型文法:无限制文法;
- 1型文法:每个产生式满足$\alpha A \beta \rightarrow \alpha \mu \beta$,其中$A$为非终结符,$\mu$不为空;
- 2型文法:每个产生式满足$A \rightarrow \beta$,其中$A$为非终结符;
- 3型文法:每个产生式有$A \rightarrow \alpha B$、$A \rightarrow \alpha$的形式(右线性文法),或者$A \rightarrow B \alpha$、$A \rightarrow \alpha$的形式(左线性文法),其中$A$、$B$为非终结符,$\alpha$为空或终结符串。
- 文法的化简:
- 形如$A \rightarrow A$的产生式;
- 无用非终结符(维护一个可以推导出终结符号串的非终结符号的集合$Q$,逐步扩大这个集合,直到不能更大);
- 不可达文法符号(维护可达符号集$R$和产生式集合$L$,$L$初始包含所有开始符号的产生式。逐步将可达符号加入符号集$R$,并标记所取的产生式,将产生式右部的非终结符对应的产生式加入产生式集合$L$,直到$L$为空或只含有标记过的产生式)。
词法分析
- 词法分析根据变换时扫描源程序的次数,分为一次扫描式和多次扫描式。
- 一次扫描式:将字符串表示的源程序,经词法分析以后,得到一个个单词系列,再作语法分析。

- 多次扫描式:将字符串表示的源程序,经词法分析以后,得到一个单词符号,立即作语法分析,再取下一个单词…
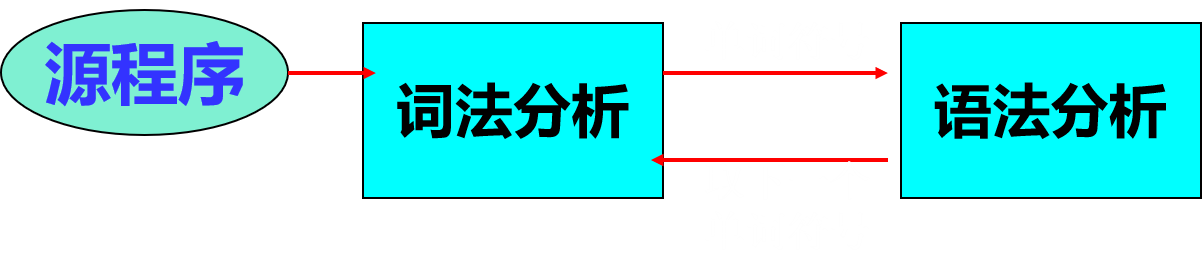
- 词法分析器的输入是字符串表示的源程序,输出是单词符号序列(单词的种别编码和自身值)。
- 词法分析器的设计过程:
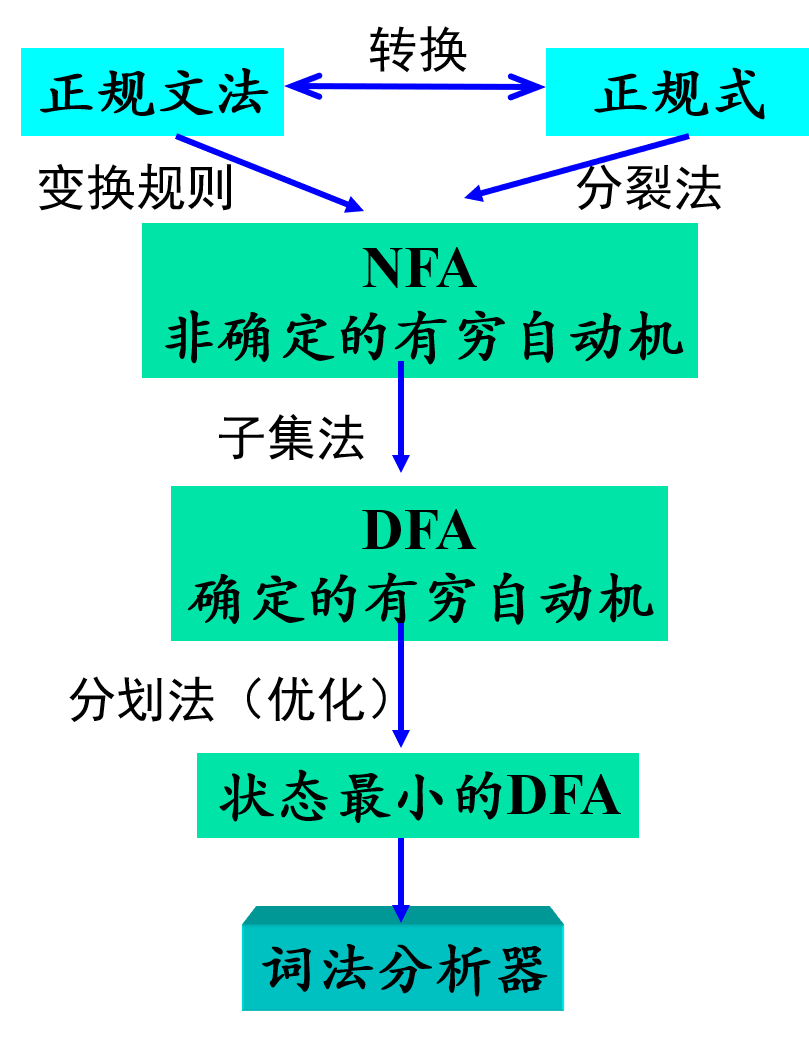
- DFA和NFA:
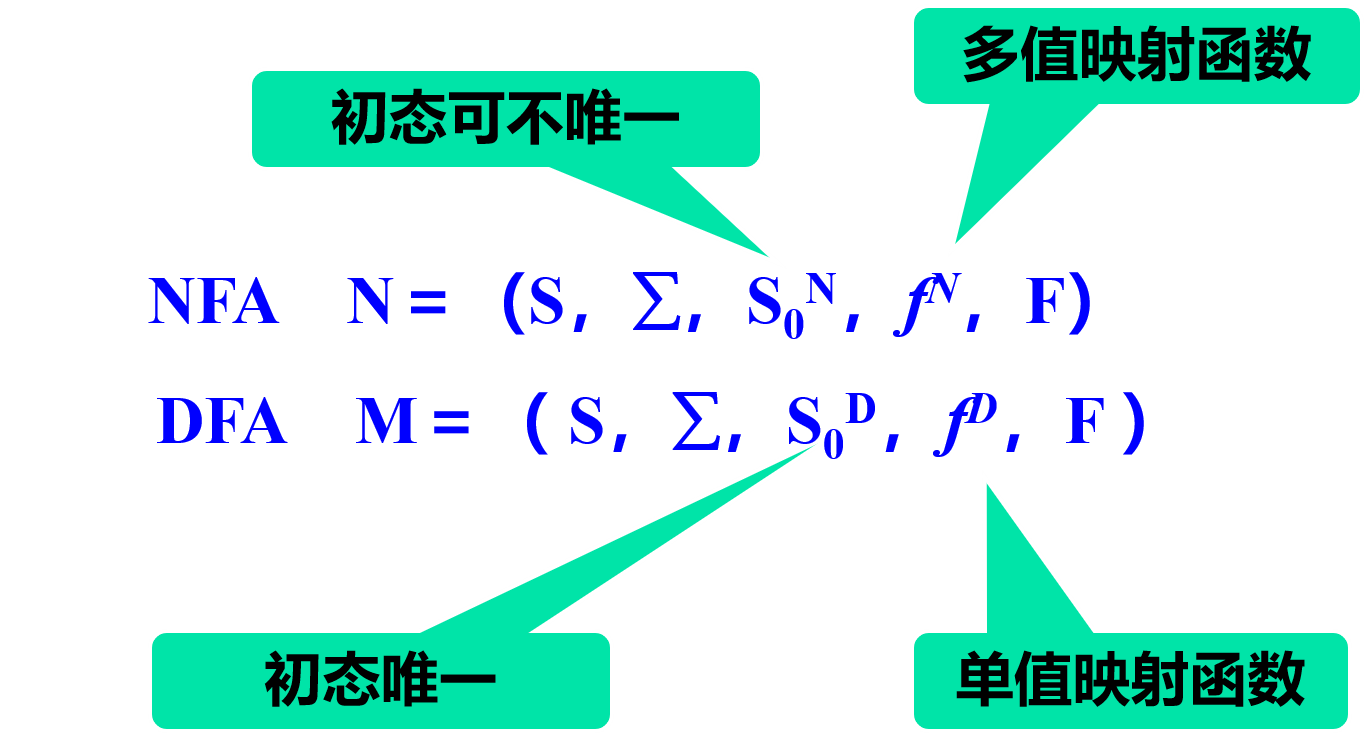
- DFA:确定的有穷自动机。$M=(S, \Sigma, f, S_0, F)$.
- $S$:状态的有穷非空集;
- $\Sigma$:有穷输入字母表;
- $f$:状态转换函数,单值映射;
- $S_0 \in S$:唯一的初始状态,非空;
- $F \in S$:终态集,可以为空。
- NFA:非确定的有穷自动机。$M=(S, \Sigma, f, S_0, F)$.
- $S$:状态的有穷非空集;
- $\Sigma$:有穷输入字母表;
- $f$:状态转换函数,多值映射,允许空移;
- $S_0 \in S$:初态集,非空,初始状态不唯一;
- $F \in S$:终态集,可以为空。
- DFA:确定的有穷自动机。$M=(S, \Sigma, f, S_0, F)$.
- 若正规式$R1$与$R2$描述的正规集相同,则$R1$与$R2$等价。

- 正规式$R \rightarrow NFA$:分裂法。引进一个初态结点$x$和终态结点$y$.

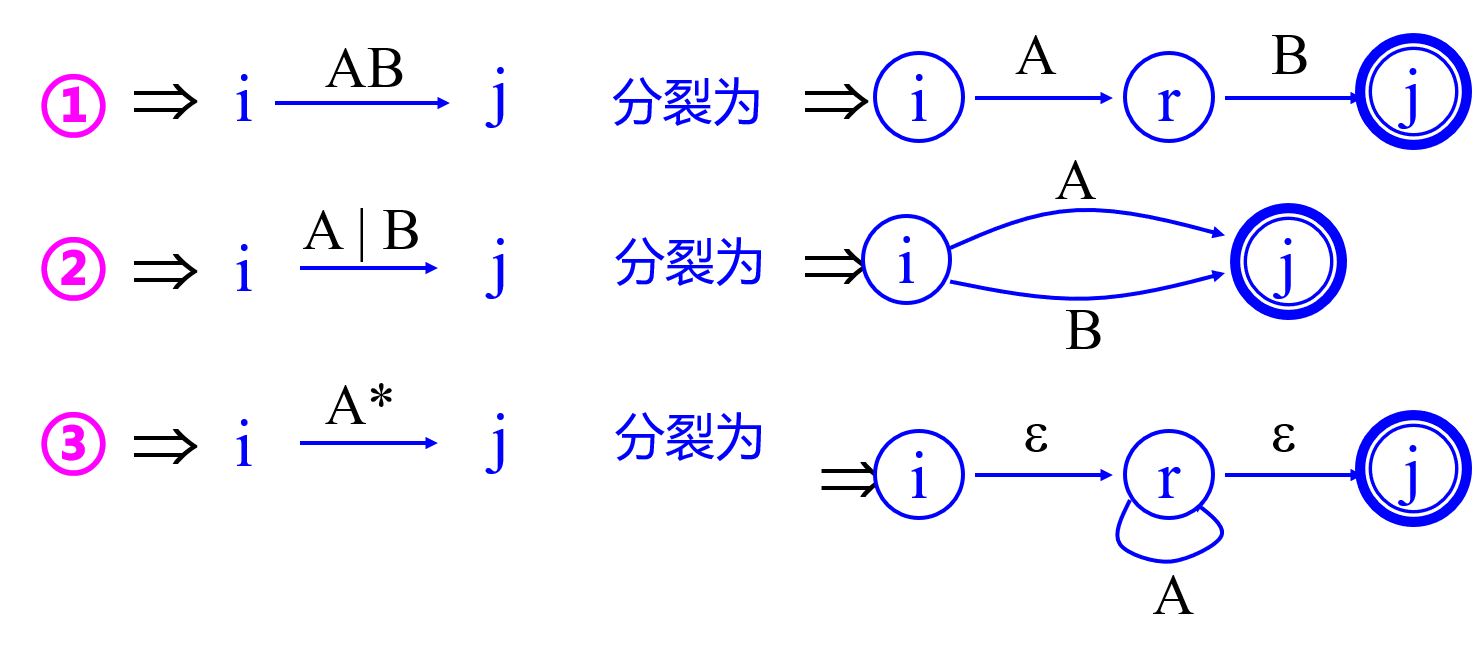
- $NFA \rightarrow DFA$:子集法。从$\epsilon -closure(x)$开始,求集合$I_a$,造表;再画状态转换表(只要含有$x$即为初态,只要含有$y$即为终态);画状态转换图($DFA$)。
- 最小化$DFA$:分划法(分割法)找等价状态。
- 右线性正规文法$\rightarrow$有穷自动机:
已知文法$G[S]=(V_N, V_T, S, P)$,增加一个状态$D$表示终止,则$FSA~M=(Q, \Sigma, q_0, f, F)$. 其中,
- $Q=V_N \cup D$,$D \notin V_N$;
- $\Sigma = V_T$;
- $q_0 = S$;
- $F = {D}$.
若$A \rightarrow aB$,则有$f(A, a) = B$;
若$A \rightarrow a$,则有$f(A, a)=D$;
若$A \rightarrow \epsilon$,则有$f(A, \epsilon)=D$.
-
左线性正规文法$\rightarrow$有穷自动机:
已知文法$G[S]=(V_N, V_T, S, P)$,增加一个状态$q_0$表示初态,则$FSA~M=(Q, \Sigma, q_0, f, F)$. 其中,
- $Q=V_N \cup {q_0}$,$D \notin V_N$;
- $\Sigma = V_T$;
- $F = {S}$.
若$A \rightarrow Ba$,则有$f(B, a) = A$;
若$A \rightarrow a$,则有$f(q_0, a)=A$.
- 自动机$\rightarrow$正规式:消结法。引进两个状态$x$,$y$,表示初态和终态。消结规则:
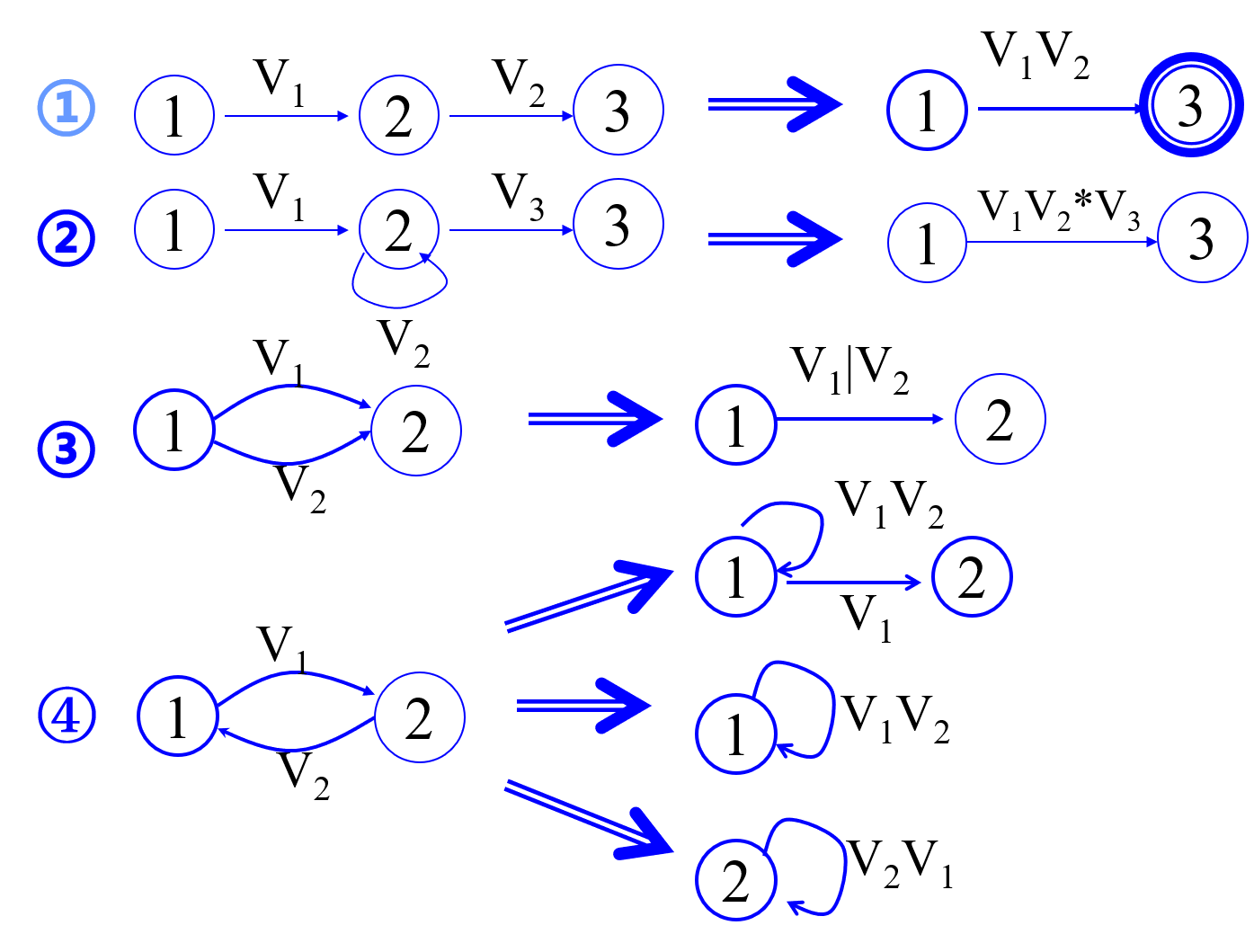
-
有穷自动机$\rightarrow$正规文法:
已知$FSA~M = (Q, \Sigma, q_0, f, F)$,求$G = (V_N, V_T, S, P)$
- 令:$V_N = Q$,$V_T = \Sigma$,$S = {q_0}$;
- 由映射函数来构造规则式:若$f(A, a)=B$,则令$A \rightarrow aB$;若$B$是终态,则令$B \rightarrow \epsilon$.
- 将识别各类单词的有限自动机合并后得到的有限自动机,可能是$DFA$,也可能是$NFA$.
- 与$DFA$相比,$NFA$的非确定性体现在允许有多个开始状态,在没有任何输入的情况下允许进行状态转换(空移)。
- $NFA$等价的$DFA$可以有多个,但是最简的$DFA$只有一个。
- 如果一个$DFA$识别的语言是一个无限集合,则该$DFA$的状态图一定含有回路。
- 词法分析器不可以发现括号不匹配、操作数类型不匹配、标识符重复声明、除法溢出,可以识别出数值常量、过滤源程序中的注释、扫描源程序并识别单词、出现非法符号错误。
自上而下语法分析
-
$First/Follow/Secect$集合的求法:3编译原理如何求first集和follow集(更正版)



- 非$LL(1)$文法到$LL(1)$文法的等价变换:
- 提公共左因子;
- 消除文法左递归(直接左递归、所有左递归)。
- 构造预测分析表:
- 对文法的每个产生式$A \rightarrow \alpha$,计算$SELECT(A\rightarrow \alpha)$;
- 若$SELECT(A\rightarrow \alpha) = a$,$a \in V_T$,则置$M[A, a]$为产生式$A \rightarrow \alpha$;
- 对所有没有定义的条目$M[A, a]$,置上$ERROR$。
- 预测分析器:

- 语法分析器接受以单词为单位的输入,产生有关信息供以后各阶段使用。
- 采用自上而下分析,必须消除回溯。
- 一个$LL(1)$文法一定是无二义的。
- 含有公共左因子的不是$LL(1)$文法,递归、右递归、2型文法是$LL(1)$文法。
算符优先分析法
- 自下而上的方法分类:算符优先分析法、LR分析法。
- 简单优先分析法是一种规范规约,但效率较低,需要考虑文法的所有符号,包括终结符和非终结符的优先关系。
- 算符优先分析法不是规范规约方法,但效率较高,只考虑终结符之间的优先关系。
- $FIRSTVT$与$LASTVT$集合

- 构造优先关系表:
- $P \rightarrow \dots ab \dots$,则$a = b$;
- $P \rightarrow \dots aQb \dots$,则$a = b$;
- $P \rightarrow \dots aQ \dots$,则对于$FIRSTVT(Q)$中的每一个$b$,有$a < b$;
- $P \rightarrow \dots Qb \dots$,则对于$LAST(Q)$中的每一个$a$,有$a > b$;
- 对于开始符的$FIRSTVT$中的每一个$a$,有$#<a$;
- 对于开始符的$LASTVT$中的每一个$b$,有$b>#$;
- $# = #$.
- 算符优先分析法的处理思想是找最左素短语。
- 分析过程:

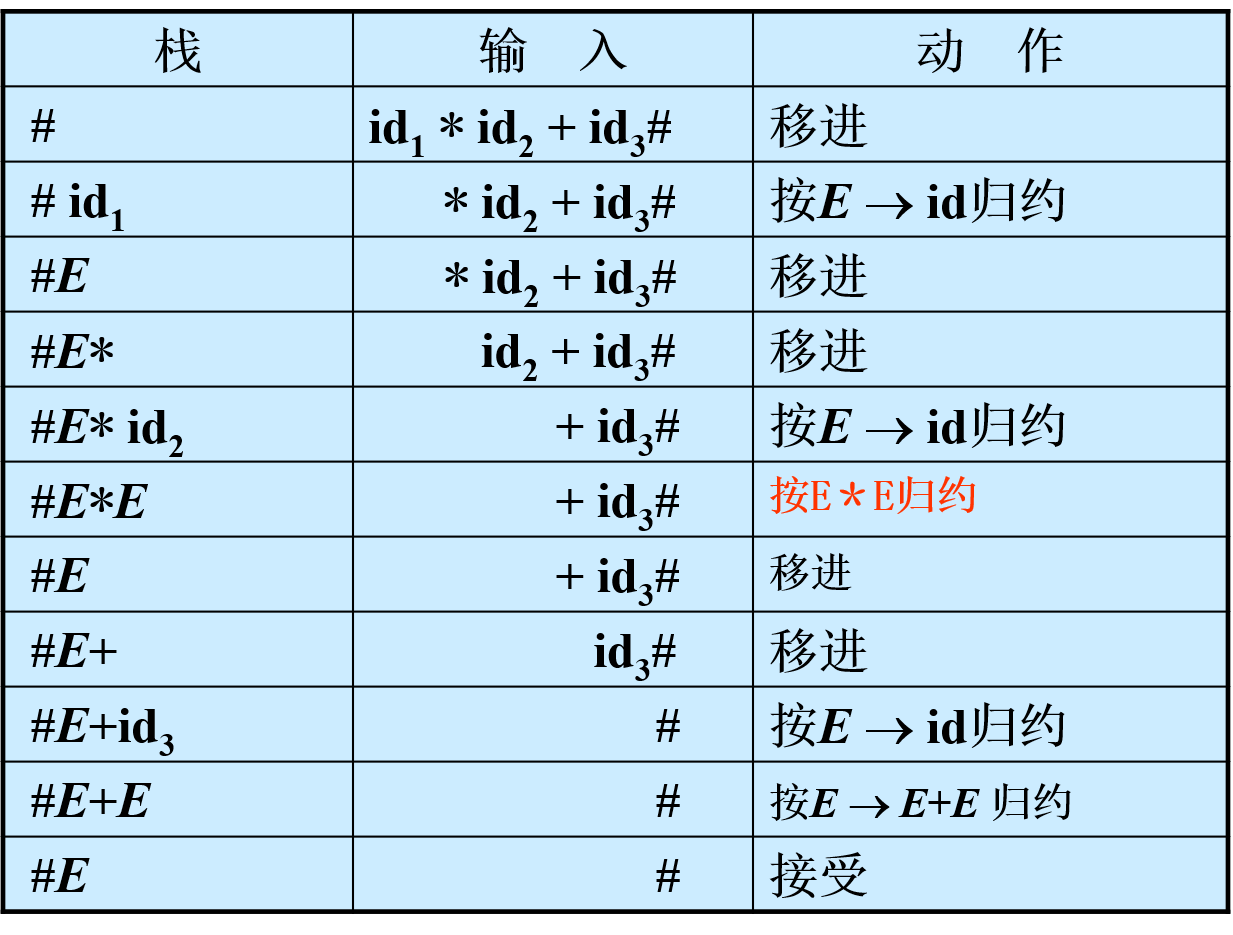
- 一个优先表不一定存在相应的优先函数。
LR分析法
- $LR$分析法是规范归约,它每次归约的是句柄。
- $LR$分析法的优点:只要是无二义的上下文无关文法都可适用、分析效率高、可以指出出错位置。
- $LR$识别过程实际上是对文法规范句型活前缀的识别过程。
- $LR(0)$项目分类:规约项目、移进项目、待约项目、接受项目。
- 规约项目:$A \rightarrow \alpha .$,圆点在最右端的项目;
- 移进项目:$A \rightarrow \alpha .x$,圆点后面为终结符的项目;
- 待约项目:$A \rightarrow \alpha .X \beta$,圆点后面为非终结符的项目;
- 接受项目:$S’ \rightarrow S.$,其中$S$为文法的开始符号,即文法开始符号的规约项目。
- 构造识别文法规范句型活前缀的$DFA$:
- 拓广文法$G$为$G’$,加入一个$0$状态$S’$,即$S’ \rightarrow S$;

- 求$DFA$的初始状态(利用闭包函数$CLOSURE$来求$DFA$每一个状态的项目集);
-
由$I_0$状态求转移函数$GO[I_0, x]= closure(J)$,即$J$为新状态。
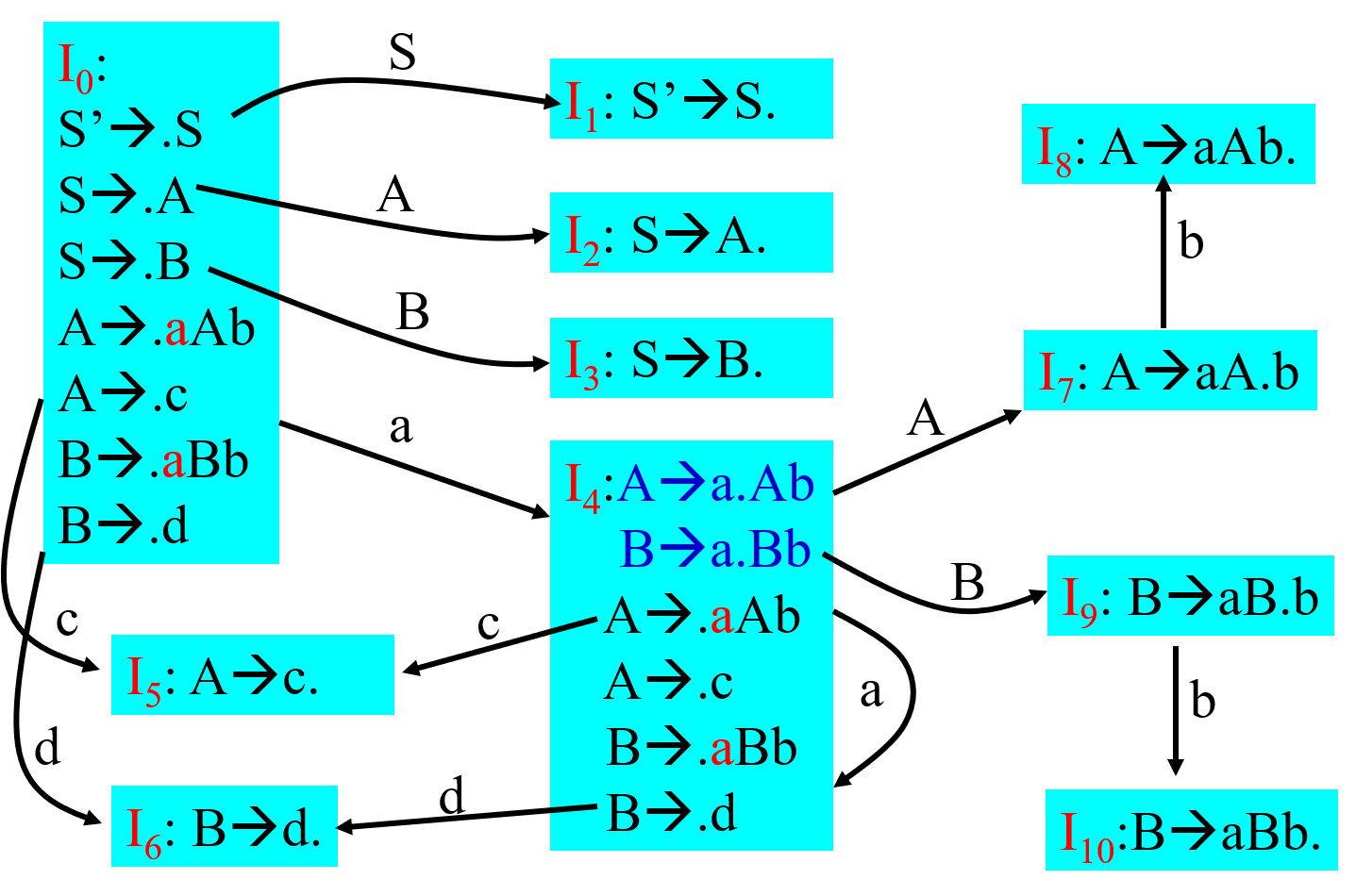
- 拓广文法$G$为$G’$,加入一个$0$状态$S’$,即$S’ \rightarrow S$;
- 构造$LR(0)$分析表:
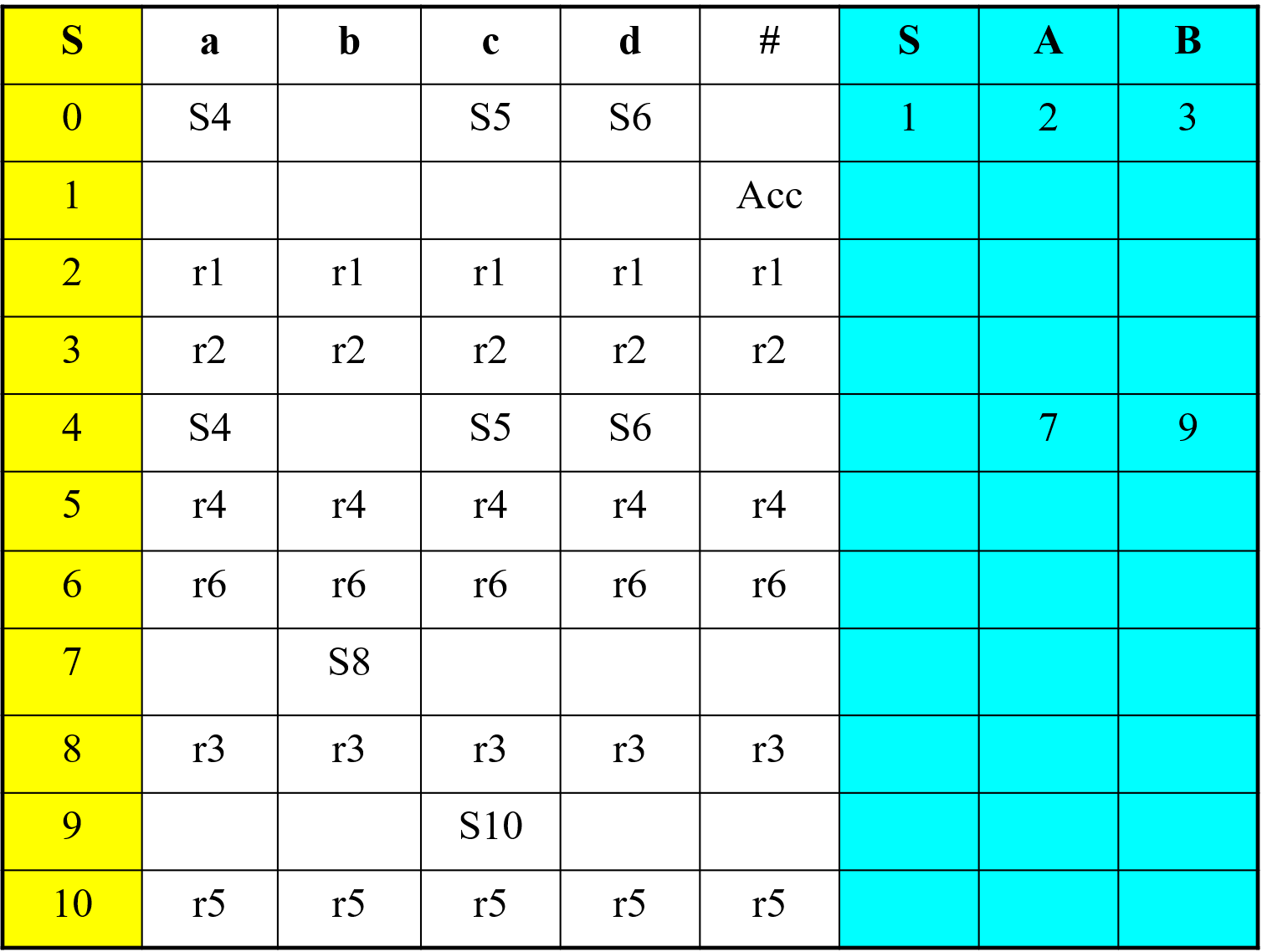
- $LR(0)$分析法表中无冲突,则该文法称为$LR(0)$文法(不是所有的上下文无关文法是否都能转换成$LR(0)$文法)。
- 构造$SLR(1)$分析表的方法:(与$LR(0)$相比)在归约时($[A \rightarrow \alpha .] \in I_k$),对任何$a \in FOLLOW(A)$的输入符号,置$action[k, a]$为$r_j$.
- 可以用$SLR(1)$方法的规则解决冲突的文法则称为$SLR(1)$文法。
- 每一个$SLR(1)$文法都是无二义的。
- $LR(1)$项目:向前再搜索一个输入符号$a$($a$在$FOLLOW(A)$中)。
- $LALR(1)$分析法:将所有同心的$LR(1)$项目集合并,求合并后的转移函数(合并后可能产生新的冲突–归约与归约冲突)。
语法制导翻译与中间代码生成
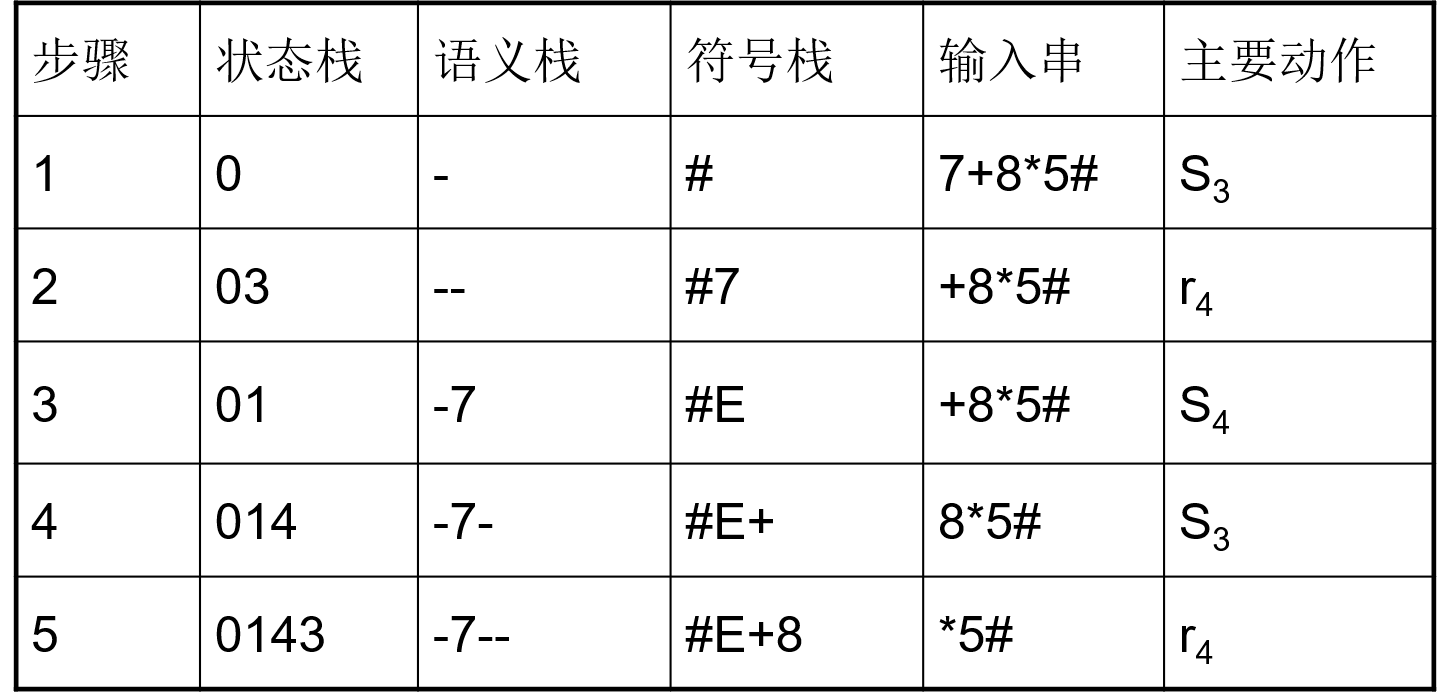
- 用$LR$语法制导翻译法得到表达式$7+8*5$的计值过程:

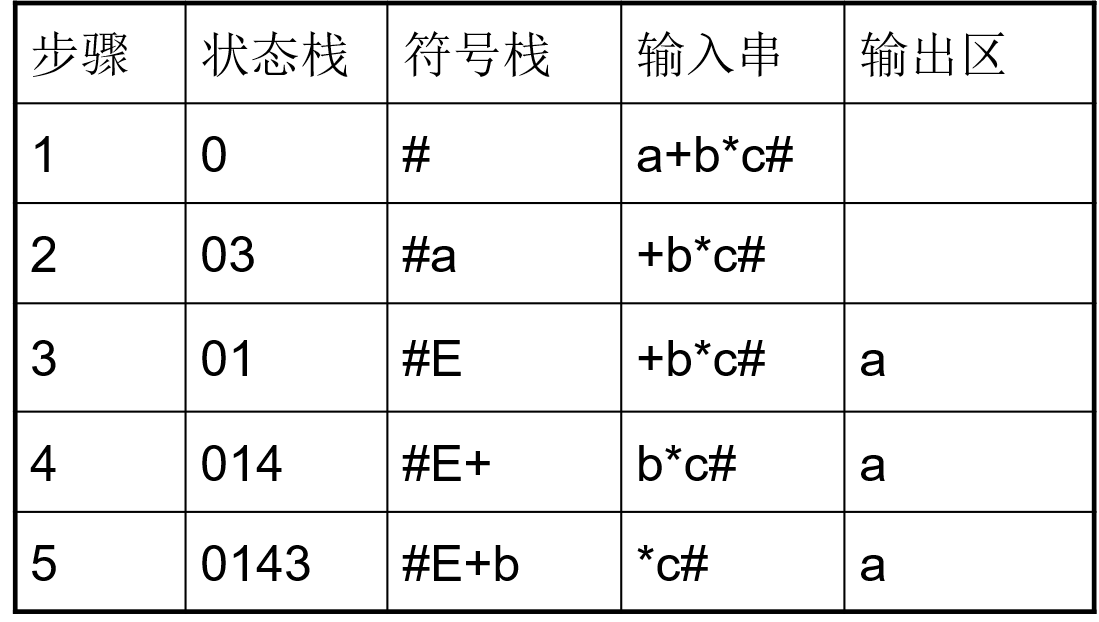
- $LR$分析制导生成逆波兰式(算术表达式$a+b*c$翻译到逆波兰式的过程):

- 三元式:$(OP, arg1, arg2)$;间接三元式:

- 四元式:$(OP, arg1, arg2, result)$. 编译系统中,有时将四元式表示成另一种更直观、更易理解的形式——三地址代码或三地址语句。三地址代码:$result = arg1~OP~arg2$;三地址语句:语句中包含最多三个量的赋值语句,每个量占一个地址。

- 中间代码生成所依据的是语义规则。
代码优化和目标代码生成
- 划分基本块的原则:
- 入口语句:
- 第一条语句
- 转移语句的第一条目标语句
- 转移语句的后续语句
- 出口语句
- 转移语句第一条目标语句的前一条语句
- 转移语句
- 停语句
删除没有被纳入某一基本块中的语句。
- 入口语句:
- 必经结点集$D(n_i)=n_i \cup (\cap D(n_k))$,其中$n_k$是结点$n_i$的所有前驱节点。
- 求控制流图中的循环:
- 求流图中各结点的必经结点集$D(n)$,要算上自身;
- 求回边$b \rightarrow a$,查看$b$的必经结点中是否包括$a$;
- 根据回边求循环:$a$是唯一的入口,$b$是出口。从出口往前找,直到找到入口为止的所有结点。
- 每个基本块都可以用一个$DAG$(有向无环图)表示。
- 代码优化的原则:等价原则、有效原则、合算原则。
- 局部优化:合并已知量、删除公共子表达式(删除多余运算)、删除无用赋值。
- 循环优化:代码外提、强度削弱、删除归纳变量。
- 全局优化:合并已知量、删除全局公共子表达式、复写传播、代码外提。
- 编译程序使用说明标识符的过程或函数的静态层次区别标识符的作用域。
- 代码优化的目的是节省时间和空间。
- 四元式之间的联系是通过临时变量实现。
- 堆式动态分配申请和释放存储空间遵守任意原则。